


In the fast-paced world of artificial intelligence, speed and accuracy are everything. Imagine a language model that not only answers your queries quickly but also delivers precise, high-quality responses, all while saving costs. Sounds like a dream?
Welcome to the era of diffusion large language models (dLLMs), led by an exciting newcomer: Inception Labs - Mercury
As digital explorers, our mission is to uncover innovative technologies that offer tangible benefits to organizations and individuals with unique offerings. By evaluating next-generation AI solutions like diffusion-based LLMs, we strive to help our partners unlock opportunities, drive efficiency, and enable rapid digital transformation. Our ongoing benchmarks and proofs-of-concept are part of this commitment, ensuring our clients get accurate, fast, and cost-effective AI capabilities for real-world use.
Traditional AI language models, like those powering ChatGPT, generate text sequentially, predicting one word at a time. While effective, this approach can become slow and resource-intensive when handling large documents or complex tasks. Mercury takes a different path by leveraging diffusion, an innovative process that generates many words simultaneously and then refines the output through multiple parallel passes. This method enables Mercury to achieve generation speeds up to ten times faster than conventional models when running on advanced GPUs, transforming the efficiency and scalability of language AI applications.
Mercury leverages the latest Transformer architecture but trains it with a diffusion technique, allowing it to generate entire sentences in a fraction of the time. It can handle very long texts (up to 32,000 tokens and beyond), making it perfect for heavy-duty tasks like summarizing lengthy research papers or extracting key insights instantly.
To experience Mercury’s capabilities firsthand, I built a Proof of Concept application using Streamlit. The goal was simple but demanding: upload any PDF document, such as a detailed 15-page research paper, and get a concise summary along with key points extracted, all within seconds. Impressively, Mercury completed this task in just 13 seconds. By comparison, ChatGPT took about 40 seconds for the same task, and other well-known LLMs like Gemini took around 35 seconds.Mercury’s exceptional speed did more than catch my attention; it demonstrated that diffusion-based LLMs are no longer theoretical. They are ready for real-world situations where both precision and rapid response times are critical.

Mercury’s PoC completed the PDF summarization task in 13 seconds.
This is about 3 times faster than ChatGPT and 2.7 times faster than Gemini.
This speed improvement highlights diffusion LLM's practical advantage for real-time applications where time is critical.
Speed isn’t just about convenience; it drastically reduces computing costs and infrastructure needs. Mercury’s efficiency means companies can deploy powerful AI without breaking the bank. Plus, its accuracy and ability to handle complex documents open doors for applications in customer support, code generation, content creation, and more.
Here is a streamlined comparison table focused on the most essential and practical features related to code generation and core capabilities for Mercury (including Mercury Coder), GPT-4o (ChatGPT), Gemini, Claude 3.5, and Grok-2 to provide a clear understanding of what each model offers and their unique strengths.
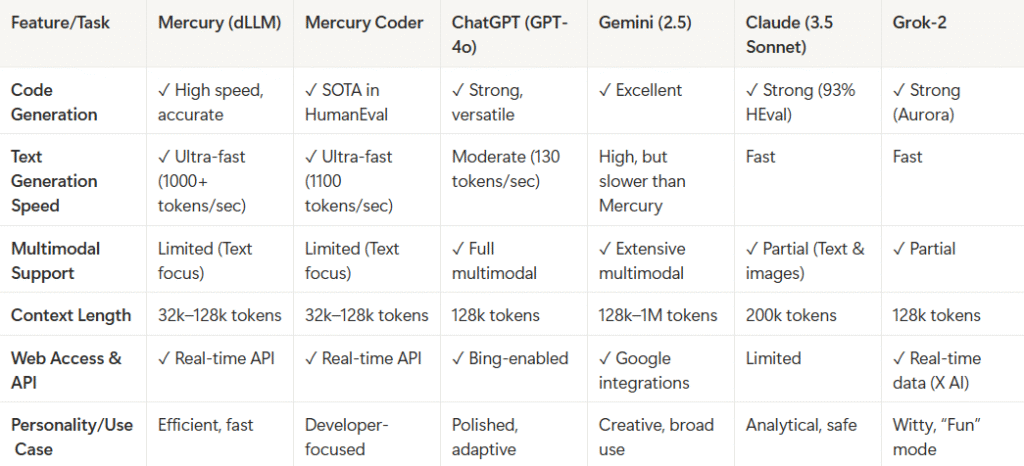
Benchmarking and tests performed by DigitalT3
While Mercury by Inception Labs is currently the leading commercial diffusion large language model (dLLM), other diffusion-based LLMs are beginning to emerge, marking a new paradigm in language generation technology. Traditional language models like GPT-4 and Gemini generate text sequentially, predicting one token at a time. In contrast, diffusion LLMs start from a noisy version of the output and progressively refine the entire sequence through parallel denoising, enabling significantly faster generation speeds up to 10 times faster in some cases.
One notable example besides Mercury is LLaDA, an open-source diffusion LLM that promotes wider experimentation due to its publicly available model weights and permissive licensing. Diffusion LLMs generally differentiate themselves by delivering ultra-fast text generation, enhanced parallel processing, and the ability to handle longer context lengths more flexibly. However, these models still face challenges such as slightly reduced reasoning accuracy on complex tasks and a less mature ecosystem compared to established transformer-based models. As diffusion LLM technology evolves, it is poised to revolutionize real-time AI applications and cost-sensitive deployments.
While diffusion LLMs like Mercury offer significant speed and scalability benefits, there are some important limitations to consider:
Reasoning accuracy may decline for longer outputs or complex tasks, sometimes requiring extra sampling steps that slow down results.
Ingesting very large contexts can be slower than traditional transformers, which may hinder document-level comprehension.
Training requires significant compute resources and large datasets, making entry harder for smaller organizations.
Compared to transformers, dLLMs have less mature ecosystems and community tooling, which can slow innovation and customization.
As with most deep learning models, interpretability is limited, making diffusion LLMs harder to audit or explain in regulated sectors.
Diffusion large language models present a compelling advantage in operational cost efficiency compared to traditional transformer-based LLMs. Conventional autoregressive models generate text sequentially, requiring extensive computation per token and longer inference times, which translates into higher energy consumption and cloud infrastructure expenses. In contrast, diffusion LLMs generate many tokens in parallel and refine outputs through iterative denoising passes. This architectural difference dramatically reduces inference latency and overall compute cycles, cutting down the cost of running large-scale language models by a notable margin. For example, Mercury’s diffusion approach delivers up to 3-10x faster generation speeds, enabling real-time AI services with significantly lower hardware resource requirements and cloud costs.
While training diffusion models can be initially more resource-intensive due to complex iterative processes, the long-term deployment benefits: reduced inference compute, improved scalability, and faster throughput; often outweigh the upfront investments. This cost efficiency makes diffusion LLMs particularly attractive for businesses seeking AI-powered applications that demand fast responses, such as coding assistants, customer support bots, and content generation tools, without incurring prohibitive runtime expenses. As diffusion LLM ecosystems mature, ongoing optimizations will likely further enhance affordability, democratizing access to high-performance AI beyond elite research labs and large enterprises.
Diffusion large language models (dLLMs) like Mercury achieve a rare balance by delivering state-of-the-art accuracy alongside generation speeds up to 10 times faster than traditional transformer models, such as GPT-4, without significantly increasing cost. Accuracy is quantitatively validated via benchmarks like HumanEval for code generation and ROUGE for summarization, where dLLMs match or outperform autoregressive models. Their parallel token generation reduces inference time and hardware usage, leading to substantial cost savings in deployment. This triad of speed, accuracy, and efficiency is measured by benchmarking identical tasks across models, assessing quality of output, generation latency, and compute resources consumed to demonstrate that diffusion LLMs optimize performance without trade-offs, enabling scalable, cost-effective AI deployment.
The journey doesn’t stop here. The next step is to integrate Mercury diffusion LLM into live projects as a compelling alternative to traditional LLMs. Its unique combination of speed, cost-effectiveness, and accuracy has the potential to reshape how we build and use AI services.
Mercury is not just another AI model; it represents a fundamental shift in language generation technology. As diffusion models continue to advance, we can expect AI tools to become faster, smarter, and more efficient, empowering businesses and developers to innovate in ways never seen before. At DigitalT3 Software Services Pvt Ltd, we are actively exploring next-gen AI technologies like diffusion LLMs to build faster, smarter, and more cost-efficient solutions for businesses.
Stay tuned as we explore this frontier together and unlock the full potential of diffusion LLMs.
We're an AI-first company that makes cutting-edge artificial intelligence work for your business.
What We Deliver:
✅ Seamless AI integration into your digital products
✅ Practical solutions that drive real business results
✅ A Team that is committed to high quality
+123 098 1234
connect@digitalt3.com





